
常见疑问(持续更新版)
下面的问答都是从我们微信群里收集的,希望能解答大家的疑问,如果大家有更多的疑问,可以在微信群里向我们提出噢
就相当于小汽车和大卡车,承载能力不同。默认的GPT都只能接受4k的token,也就是输入输出加起来最多只能有4000个token,多了就得下一次再输出了;16K是普通3.5的4倍,如果你涉及到大量文本的输入输出,选16k的模型效果会更佳噢。
(以下回答来自GPT)
OpenAI的GPT-3.5模型使用Byte Pair Encoding (BPE)进行文本编码,这种编码方式在处理不同语言时的效率可能会有所不同。BPE是一种子词分词方法,可以将词语进一步划分为更小的可重复部分。对于汉语等字形语言,一个token可能只包含一个字符,但对于英语等词素语言,一个token可能包含一个或多个单词。
GPT-3.5模型的4K token限制是指最多可以处理4000个BPE tokens。对于中文,一般来说,1个token大约等于1个汉字。所以,4000 tokens大约可以处理4000个汉字。但是,请注意,这是一个大概的数值,具体的数量可能会受到特殊字符、标点符号等因素的影响。
学术版是放在huggingface(https://huggingface.co/spaces/bioinfoark/academic)上的,会受到使用者的网络因素影响。
如果你遇到打开慢的情况,可以访问一下这个网址:https://ping.chinaz.com/huggingface.co 看看你们当地访问huggingface的网速如何。有些地方网速确实不行,这就不是我们能解决的了。后期等人手充足我们会考虑额外搭建一个离国内近一些不受网络影响的备用站点。
现在GPT4的价格是GPT3.5的20-30倍。即使是一模一样的输入和输出,GPT4扣除的点数会是3.5的20-30倍。
如果想知道自己发送的内容和GPT回复的内容使用了多少点数的话,可以用这个网站计算:
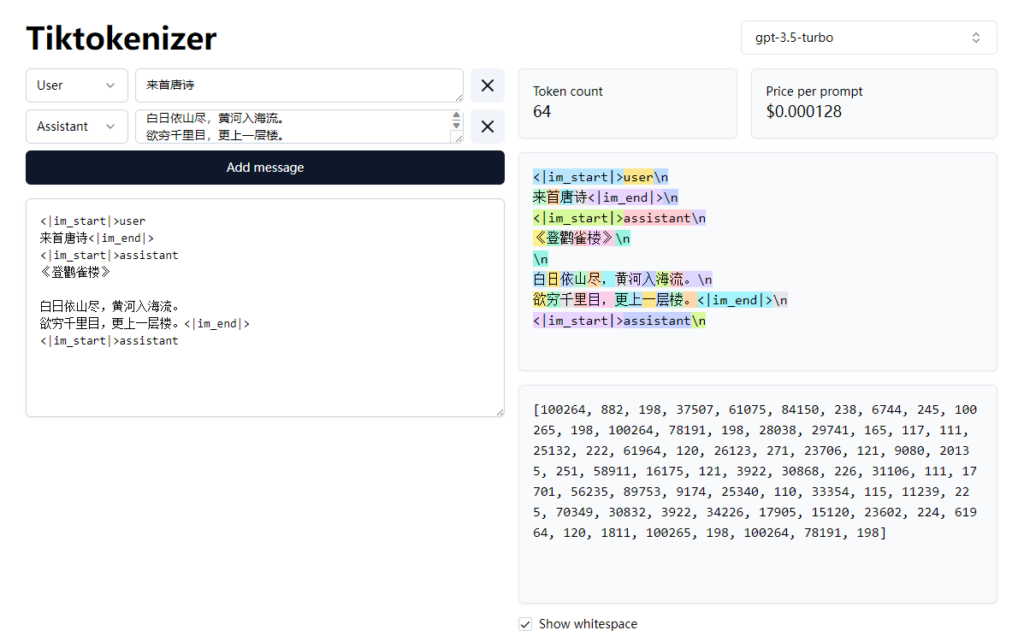
例如,当你跟GPT说“来首唐诗”,GPT回复你登鹳雀楼的诗文之后,右边会告诉你这次交互使用了64个token。我们1P对应100 token。
如果你指的是用自然语言直接生成生信相关的图的话,目前为止(2023年9月)没有任何人能提供这样的服务。
如果你指的是code interpreter, 即你上传数据文件之后,用自然语言指挥gpt生成代码、处理文件、甚至绘制图片(例如条形图、柱状图),那么这个服务我们正在测试,之后会邀请一些内测用户,通过内测之后再开放给大家使用。
来自bioinfoark@gmail.com 的邮件反馈。
回复如下:
关于您询问的问题,GPT点数是按照交互的字数进行计算和消耗的。例如1000P代表用3.5模型的时候可以输入输出加起来10w的中/英文字符。这是一个比较粗略的估计。
如果您使用的是GPT4,那么费用会是3.5模型的20~30倍。
另外就是上下文内容过多也会导致消耗量增加。例如第一个问题问:”一加一等于几“,GPT回答:2 。当你第二个问题问”为什么不等于3“时,GPT为了理解上下文,第二轮的实际输入是第一轮问答的所有内容加上第二轮的提问。因此,随着交互次数和内容的增加,点数消耗是会逐渐增加的。目前市面上所有的大模型都是基于这个方法来实现”智能化理解上下文“的。
因此如果交互的问题不相关,则可以考虑删除掉不相关的内容/开启新一轮的对话之后再进行下一轮交互。
就是同一个东西呀。它开源归开源,您如果想要使用也还是要消耗点数的。您在我们这里购买的点数除了可以在标准版的chatGPT里使用,也可以在GPT学术版里使用,接下来会支持更多的其他工具(例如已经支持的DeepGPT和将会支持的绘图功能)。我们主打的就是降低大家使用Ai工具的门槛,让大家能追上这波Ai的浪潮。这有点像吃自助餐,只要你进来了,吃什么任君挑选,我们主要负责提供尽可能多的菜品和选择供大家享用。
我们给大家节省了配置的麻烦,直接把服务都搭好了,你拿到key就可以直接使用了
(以下回答来自GPT)
我们的计量单位1P是等于100 tokens,那么1000P等于100,000 tokens。
对于中文,每个token通常对应一个字符,所以100,000 tokens大约可以处理100,000个中文字符。
对于英文,由于GPT-3.5使用的是Byte Pair Encoding (BPE)编码,一个token可以包含一个词或一个词的部分。因此,一个token可能包含多个英文字符。实际的字符数量会根据英文文本的具体内容(例如单词的长度和复杂性)而变化。一般来说,可以粗略估计,每个token包含5个英文字符(包括空格和标点符号)。因此,100,000 tokens大约可以处理500,000个英文字符。
对于代码,一个token可能包含一个字符,一个标识符(例如变量名),或者一个操作符。实际的数量会根据代码的具体内容而变化。对于代码,我们可以暂时将其视为等同于英文字符处理,因此100,000 tokens也大约可以处理500,000个字符。但请注意,这只是一个粗略的估计,实际的数值可能会有所不同。
最后,需要注意的是,这些都是粗略的估计,实际的数量可能会因具体文本内容的不同而有所变化。
有的。我们接下来会录制一系列视频,把我们提供的每个功能都给大家介绍到,并提供一些使用的案例。
这是所有的Ai都要面临的问题,如果你确实担心你的数据,那最佳方案是在你本地搭建一个不联网的Ai应用来供您自己使用,这将会是最保险的方案。
我们本来主打的就是可以无限制地使用GPT4,并且提供联网的功能。如果你的需求只是使用不能联网的GPT3.5的话,那你当然可以选择其他人提供的服务啦。每个人的需求不一样 完全可以理解。现在即使开了openai的会员,每个月交20美金,能够使用GPT4的次数也是有限的,三小时内只能交互25次。(最近调高到了50次/3小时)
请给我们的邮箱写邮件:bioinfoark@gmail.com
现在GPT实现理解上下文的方法特别地粗暴。
举个例子,模拟一个场景:
问GPT:西游记是不是四大名著?
GPT答:是的,xxxxxx(此处省略一堆字数)
第二个问题问GPT:这本书主要讲了什么内容?
此时,GPT是怎么知道你指的【这本书】是什么内容呢?其实GPT就是把第一个问题的提问和回答加上第二个问题都输给GPT再去问了一遍,然后就知道上下文了,就可以理解你指的【这本书】是什么并回答你了。
因此,前面聊的内容越多,GPT消耗token的数量也就会越多。这也是为什么要设置【最大历史上下文数量】的原因。
不设置的话,消耗的token会非常恐怖,并且,GPT普通版的上下文只有4000 token。
但是设置最大上下文数也有问题。当交互次数超过最大上下文数之后,GPT会忘了你前面最开始问的是什么。
这个是GPT或者说目前所有大语言模型的通病哦。
TBA